Generative AI and Prompt Engineering
Generative AI and Prompt Engineering
Agentic AI — Ram N Sangwan
Overview
Generative AI Concepts
Prompt and Prompt Engineering
K-Shot Prompts
Max Tokens, Temperature
Top-K and Top-P
Artificial Intelligence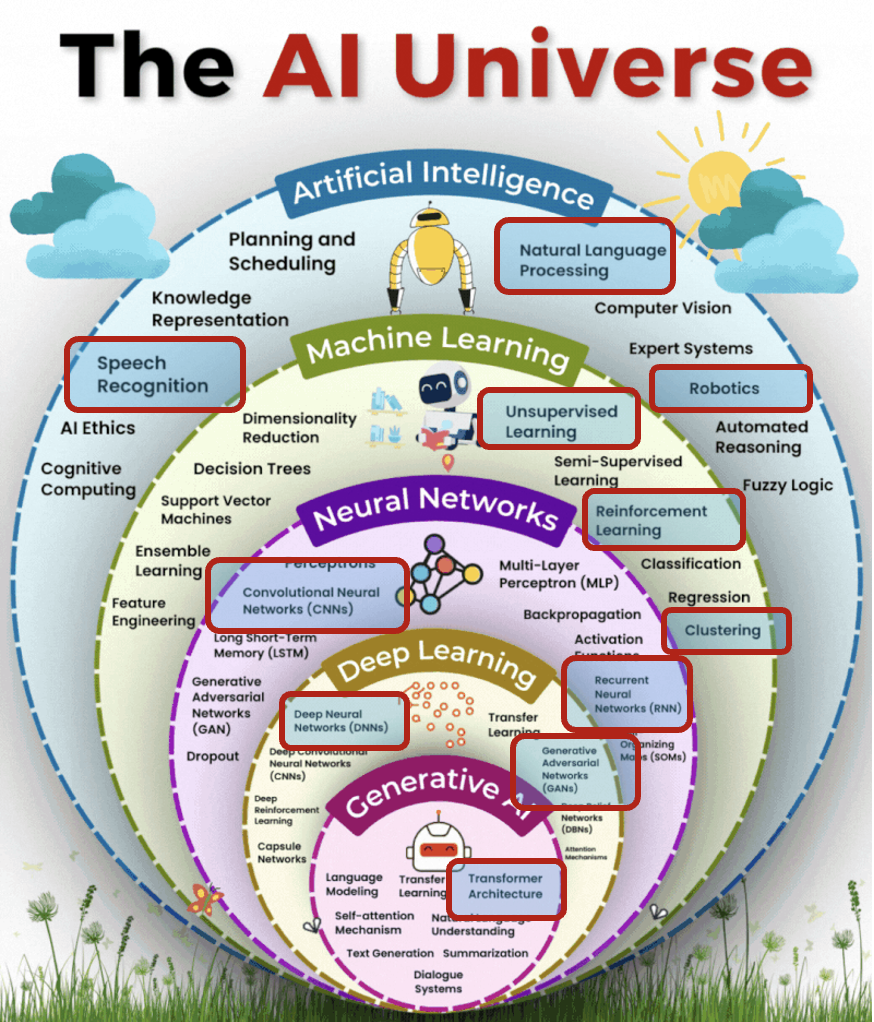
Ability of machines to mimic the cognitive abilities and problem-solving capabilities of human intelligence.
Machine Learning
A subset of AI that focuses on creating computer system that can learn and improve from experience. Powered by algorithms that incorporate intelligence into machines.
Machine Learning and its Use Cases
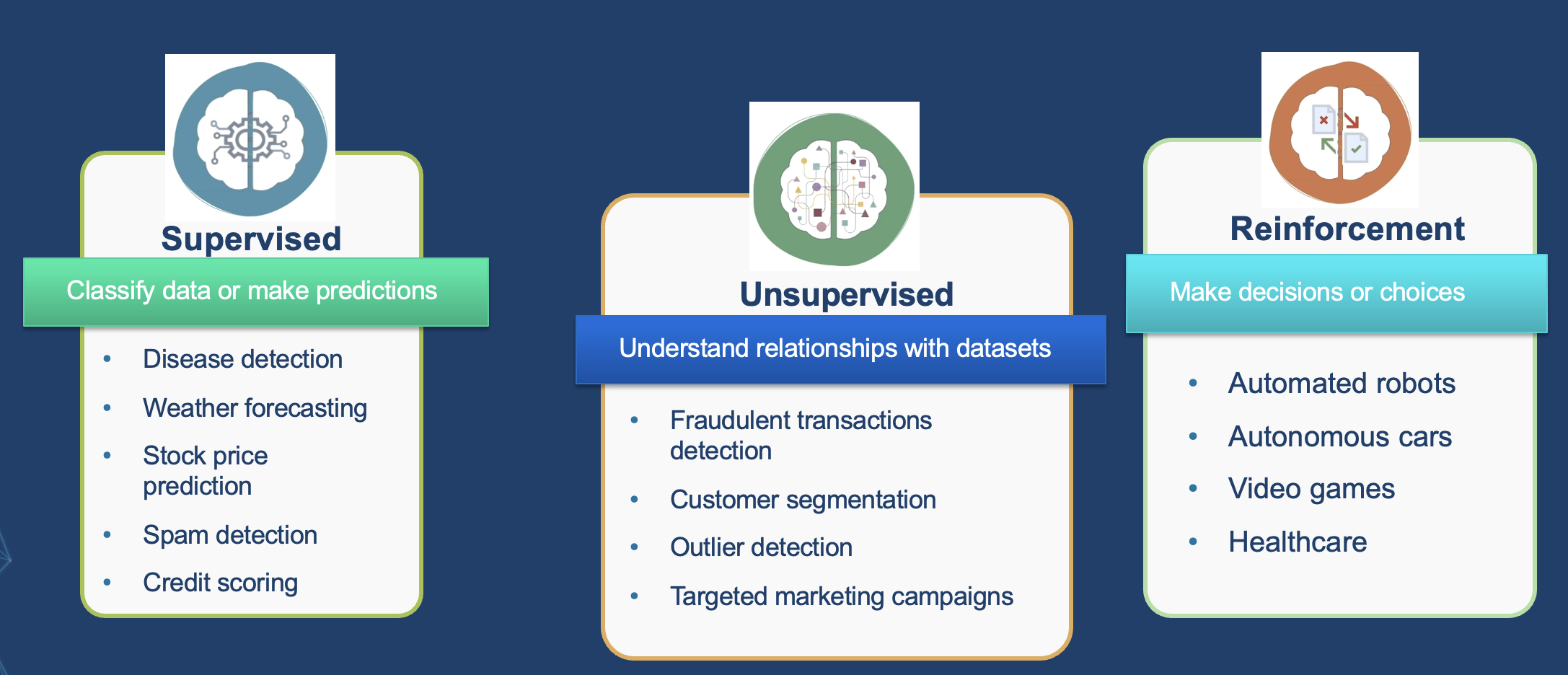
- Classify data or make predictions
- Understand relationships with datasets
- Make decisions or choices
Vectors
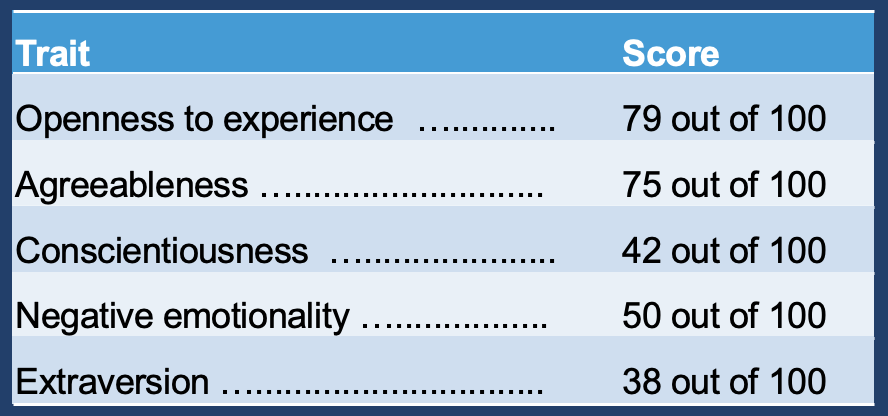
On a scale of 0 to 100, how introverted/extraverted are you? Have you ever taken a personality test like Big Five Personality Traits?
These tests ask you a list of questions, then score you on number of axes, introversion/extraversion being one of them.
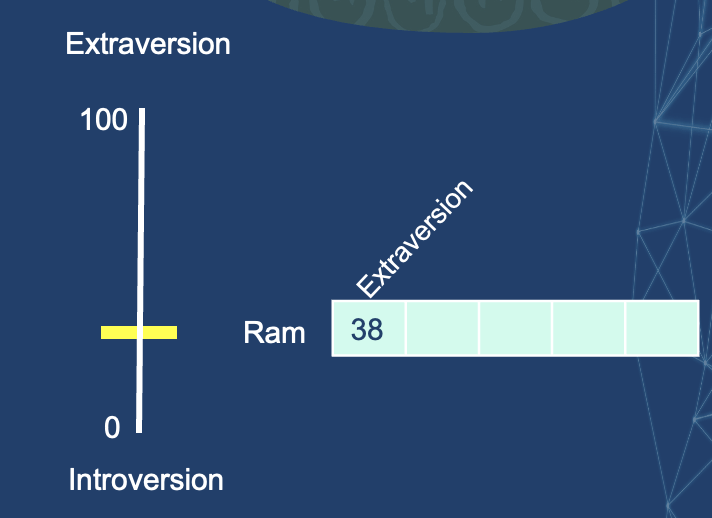
Imagine I’ve scored 38/100 as my introversion/ extraversion score. We can plot that in this way.
Let’s switch the range to be from -1 to 1.

How well do you feel you know a person knowing only this one piece of information?
Not much.
Let’s add another dimension – the score of another trait.
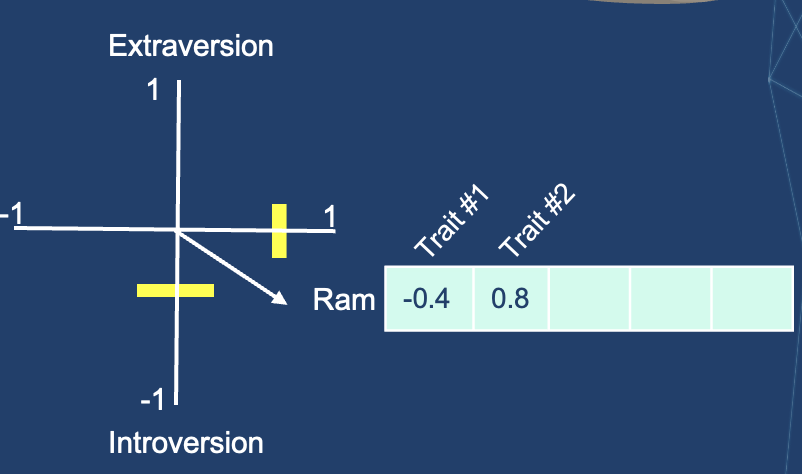
- We can represent two dimensions as a vector from the origin to that point.
- I’ve hidden which traits we’re plotting so that you get used to not knowing what each dimension represents but still getting a lot of value from the representation.
- The usefulness of such representation comes when you want to compare me with others.
- Say, I am looking for someone with a similar personality.
- Which of the two people is more like me?
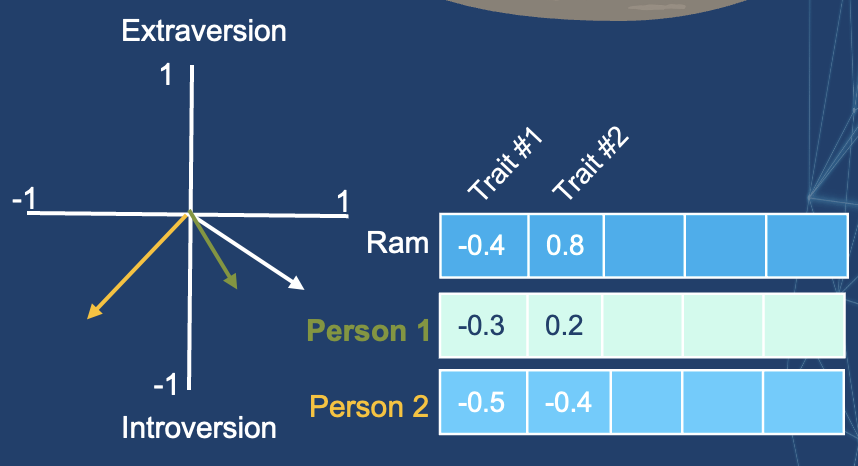
A common way to calculate a similarity score for vectors is cosine_similarity.

Person #1 is more like me. Vectors pointing at the same direction (length plays a role as well) have a higher cosine similarity score.
Two central ideas:
- We can represent people (and things) as vectors of numbers (which is great for machines!)
- We can easily calculate how similar vectors are to each other
Prompt
The text provided to an LLM as input, sometimes containing instructions and/or examples.
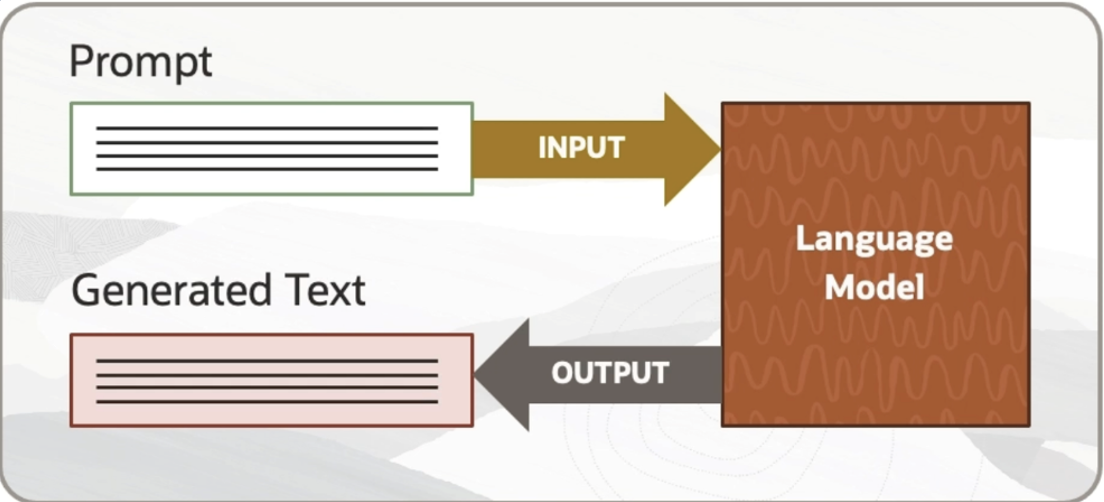
Prompt Engineering
The process of iteratively refining a prompt for the purpose of eliciting a particular style of response. Prompt engineering is challenging, often unintuitive, and not guaranteed to work. At the same time, it can be effective; multiple tested prompt-design strategies exist.
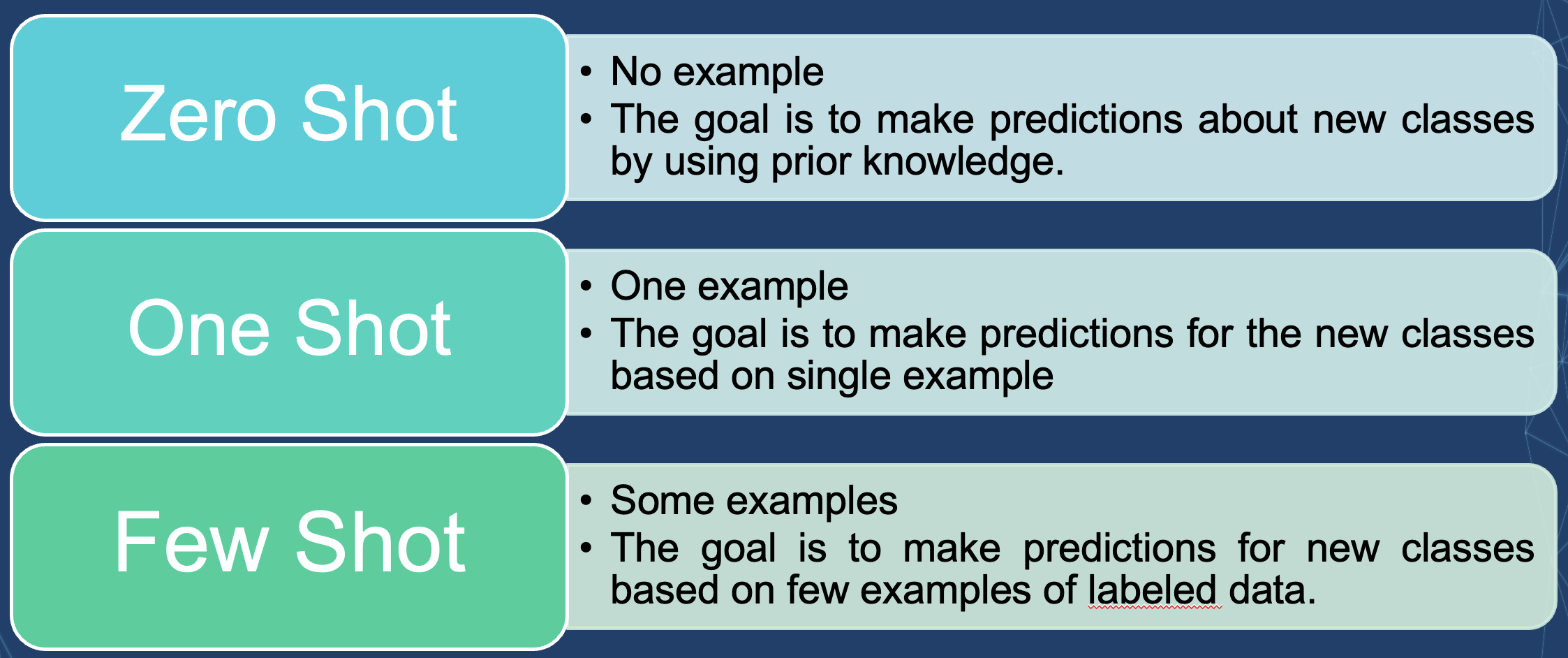
In-Context Learning and K-Shot Prompting
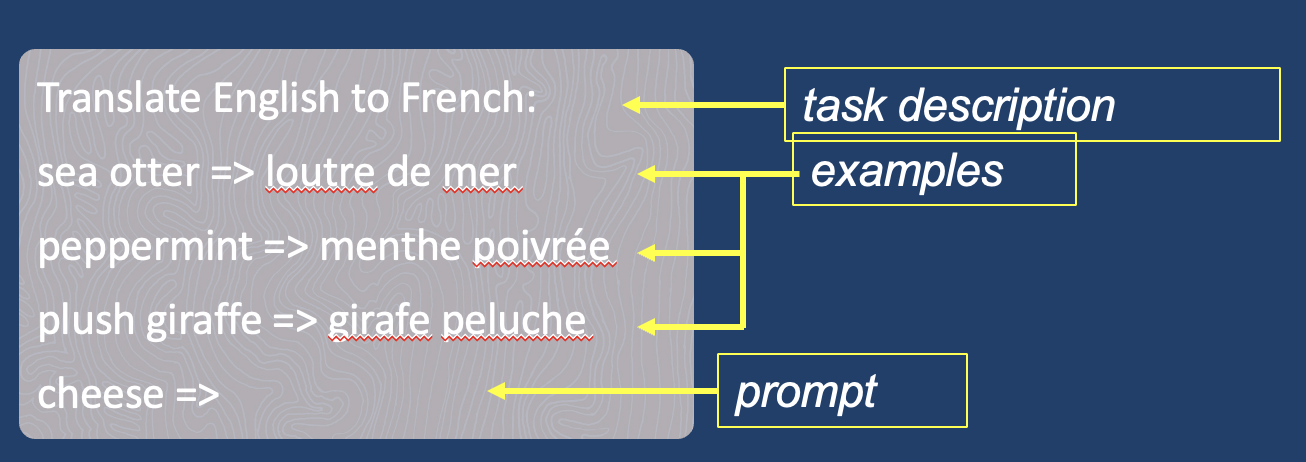
In-context learning — Conditioning an LLM with instructions and/or demonstrations of the task it is meant to complete.
K-Shot Prompting — Explicitly providing k examples of the intended task in the prompt.
Few-shot prompting is widely believed to improve results over 0-shot prompting.
 |
 |
 |
 |
Tokens
One token can be a part of a word, an entire word, or punctuation.
A word such as “friendship” is made up of two tokens — “friend” and “ship.”
Number of Tokens/Word depend on the complexity of the text.
Simple text: 1 token/word (Avg.)
Complex text (less common words): 2-3 tokens/word (Avg.)
Many words map to one token, but some don't: indivisible.
Language models understand tokens rather than characters.
A common word such as “apple” is a token.

Generation Controls
Max Tokens
This is the maximum length of the output that the model can generate in one response, measured in tokens. If the max tokens limit is set, the model will not generate more tokens than that limit in its response.
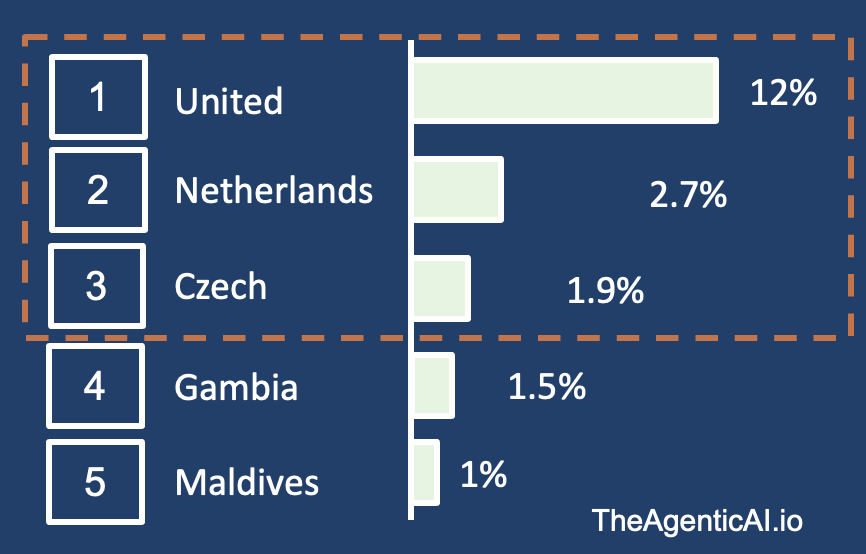
Top-K
If Top k is set to 3, model will only pick from the top 3 options and ignore all others. Mostly pick “United” but will pick “Netherlands” and “Czech” at times.
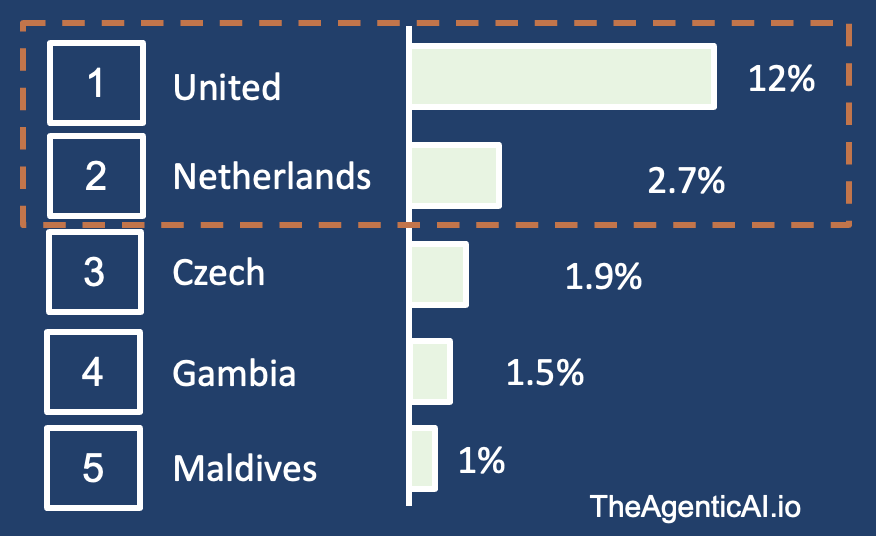
Top-P
If p is set as .15, then it will only pick from United and Netherlands as their probabilities add up to 14.7%. If p is set to 0.75, the bottom 25% of probable outputs are excluded.
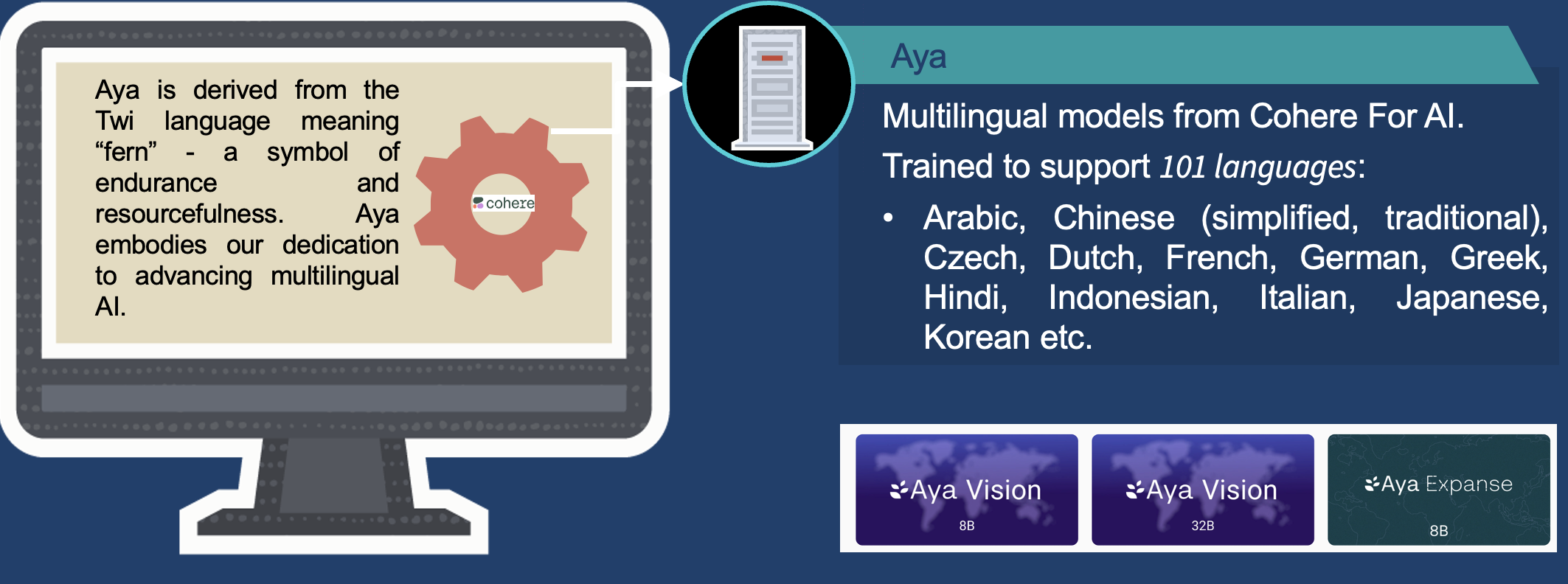
Cohere Platform
![]()
 |
 |
 |
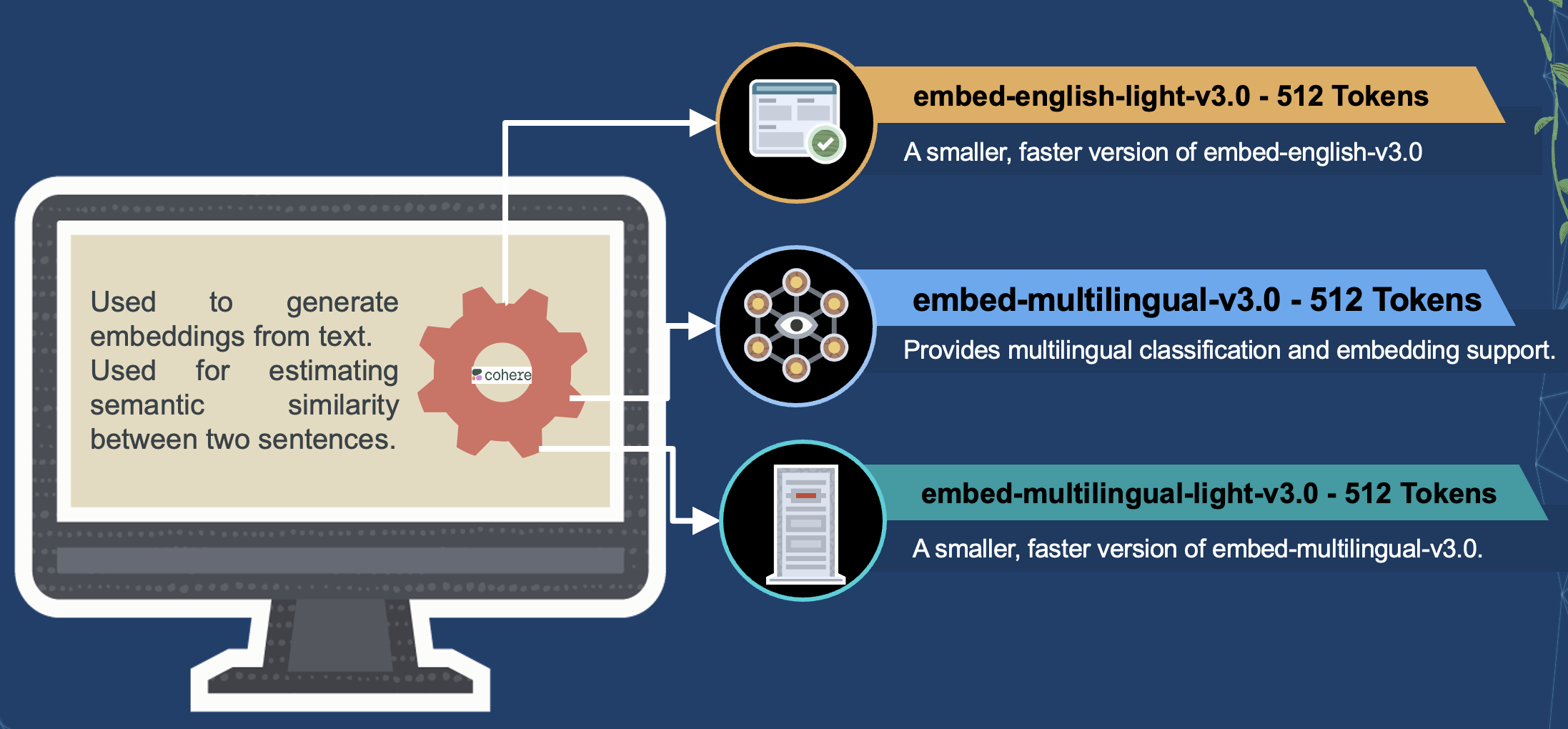
Cohere provides a powerful API for its models that integrates language processing into any system.
Cohere develops large-scale language models and encapsulates them within an intuitive API.
You can tailor these models to suit your use cases.
Cohere provides a range of models that can be trained and tailored to suit specific use cases.


Setting Up Cohere
import osimport cohere from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) co = cohere.Client(api_key=os.getenv('COHERE_API_KEY')) # New Chat API V2 co_v2 = cohere.ClientV2(api_key=os.getenv('COHERE_API_KEY'))
Define the Cohere client with the API key.

Embeddings Endpoint
response = co.embed( texts=['hello', 'goodbye'], model='embed-english-v3.0', input_type='classification' )
Agentic AI — Recent Developments
- Planning → Acting → Observing → Reflecting loops
- Multi-agent collaboration
- Tool calling across APIs and software systems
- Persistent memory
- Human oversight and governance
- Evaluation based on task success